GPU Data Loading
Low Data Loader Efficiency means fewer iterations on the model. Even the best teams spend tremendous amounts of human capital building, maintaining and adapting custom solutions - and their GPU still sits idle.
The state of the art data loading solutions are complex, brittle and hard to maintain.
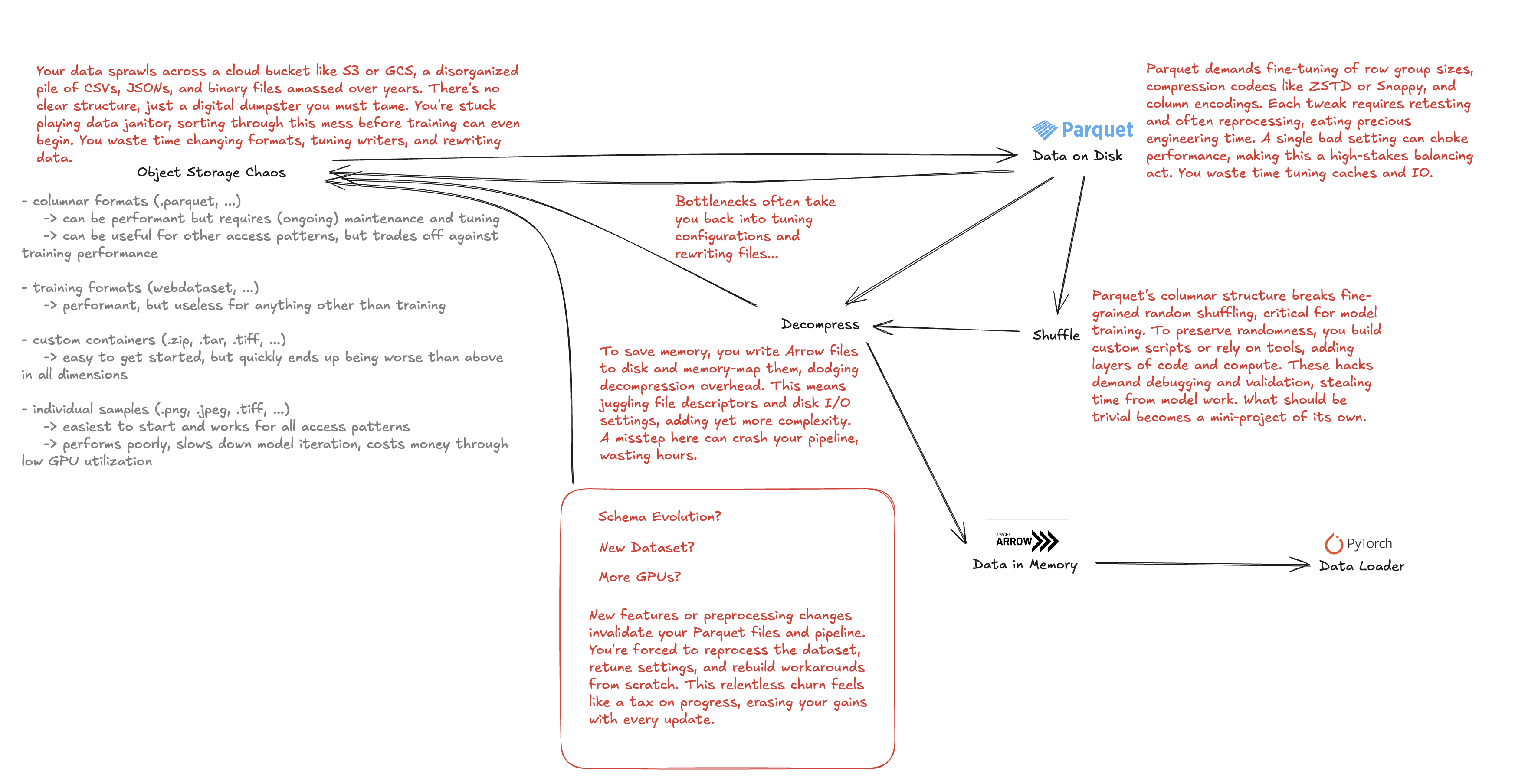
Spiral is designed to deliver maximal throughput and elasticity enabling efficient training cycles.
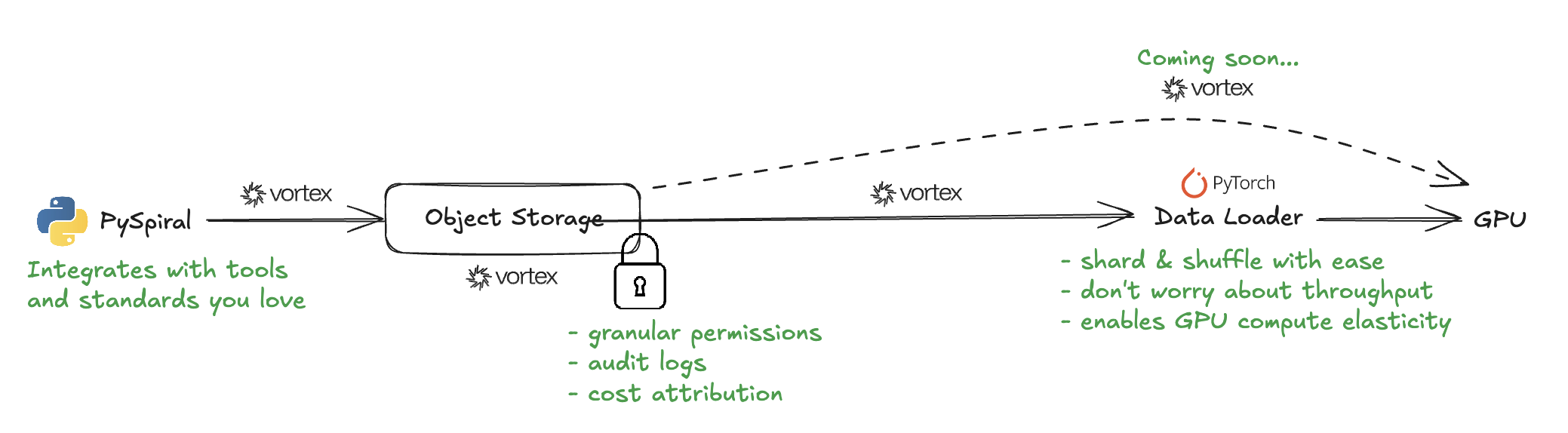
Training on (Live) Tables
Tables offer a powerful and flexible way for storing dynamic massive and/or multimodal datasets, and an easy way to obtain high throughput production-ready data loader. Scan object integrates with many training frameworks.
We recommend starting with a Scan object which provides a simple interface for getting a PyTorch-compatible DataLoader.
from spiral import Spiral, SpiralDataLoader
from spiral.demo import images
sp = Spiral()
table = images(sp)
scan = sp.scan(table)
data_loader: SpiralDataLoader = scan.to_data_loader(seed=42, batch_size=32)Unlike PyTorch’s DataLoader which uses multiprocessing for I/O (num_workers), SpiralDataLoader leverages Spiral’s
efficient Rust-based streaming and only uses multiprocessing for CPU-bound post-processing transforms.
Key differences from PyTorch’s DataLoader:
- No num_workers for I/O (Spiral’s Rust layer is already multi-threaded)
map_workersfor parallel post-processing (tokenization, decoding, etc.)- Explicit shard-based architecture for distributed training
- Built-in checkpoint
CPU-bound transforms such as tokenization can be parallelized, similar to num_workers in PyTorch, while remaining
compatible with Spiral’s efficient I/O.
import pyarrow as pa
# CPU-bound batch transform function
def tokenizer_fn(rb: pa.RecordBatch):
# tokenize the rb
return rb
data_loader: SpiralDataLoader = scan.to_data_loader(transform_fn=tokenizer_fn, map_workers=8)Built-in checkpointing allows resuming training from the last processed record in case of interruptions.
loader = scan.to_data_loader(batch_size=2, seed=42)
for i, batch in enumerate(loader):
if i == 3:
# Save checkpoint
checkpoint = loader.state_dict()
# ...
# Resume from checkpoint
loader = scan.resume_data_loader(checkpoint, batch_size=32)A lower-level interface such as Torch-compatible IterableDataset is also available.
from torch.utils.data import IterableDataset, DataLoader
iterable_dataset: IterableDataset = scan.to_iterable_dataset()
data_loader = DataLoader(iterable_dataset, batch_size=32)Distributed Training
Distributed training is natively supported.
data_loader: SpiralDataLoader = scan.to_distributed_data_loader(seed=42, batch_size=32)Optionally, world size and rank can be specified explicitly.
from spiral import World
world = World(rank=0, world_size=64)
data_loader: SpiralDataLoader = scan.to_distributed_data_loader(
world=world, seed=42, batch_size=32
)Training on filtered data with a higly selective filter in distribute setting can lead to unbalanced shards across nodes.
In such cases, it is recommended to provide shards through shards arg to ensure balanced data distribution.
Shards can be obtained from scan via shards() or built using compute_shards().