Spiral Table Format
Spiral Tables are designed as a table format, similar to Apache Iceberg. The client is configurable with a pluggable metastore, and the SpiralDB server provides a reference implementation over HTTP.
Data Model
The data model is tabular, requiring a mandatory primary key and an optional partitioning key.
A primary key is a column or a group of columns used to uniquely identify a row in a table. A partitioning key is simply a prefix of the primary key that forces a physical partitioning of data files. From here on, we will refer to the primary (and partitioning) key as the “key”.
Schema Tree & Column Groups
The table’s schema forms a tree, with a column at each leaf. Sibling leaves are grouped together into a column group. At a basic level, column groups can be thought of as independent tables that are efficiently zipped together at read time.
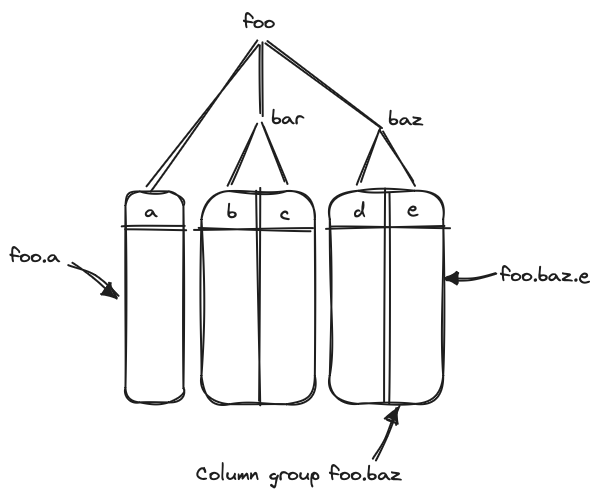
Storage Model
The storage model consists of key and column group tables, each partitioned and sorted by the key. At a basic level, a read operation performs an outer join on these tables.
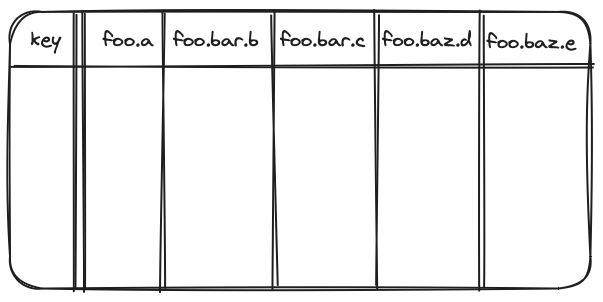
Keys (and column groups) are stored as a log-structured merge (LSM) tree.
This is a data structure that consists of sorted runs of data. Within each sorted run, all keys are sorted and unique. But between runs, keys may overlap. Periodic compaction of an LSM tree attempts to read overlapping sorted runs, merge them together, and write them back as a single non-overlapping run. This improves read performance since the overlapping keys must be merged at read time.
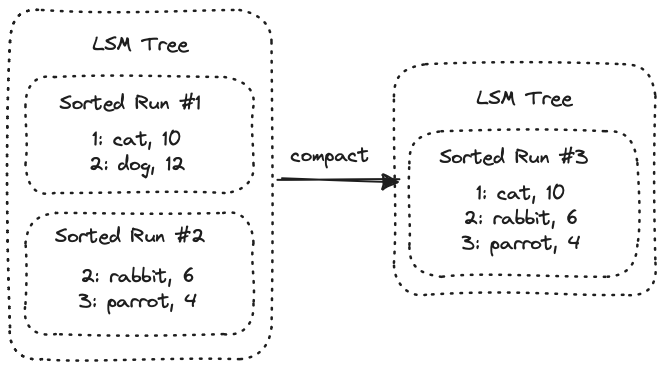
In the context of keys, each sorted run represents a key space.
Key Spaces
Key spaces store the actual key data, separately from the column group data. This separation allows us to reuse key spaces across multiple column groups and reduce the number of outer joins required at read time.
Key spaces have an upper bound on the number of keys they can store, which depends on the level of the LSM tree.
Furthermore, each key space is content-addressed, allowing us to deduplicate identical runs of keys across multiple column groups. (not yet implemented)
Key spaces are stored as a partitioned Merkle hash trie, enabling us to quickly join dense runs of identical keys. (not yet implemented; currently, key spaces are stored as a collection of key files)
Column Groups
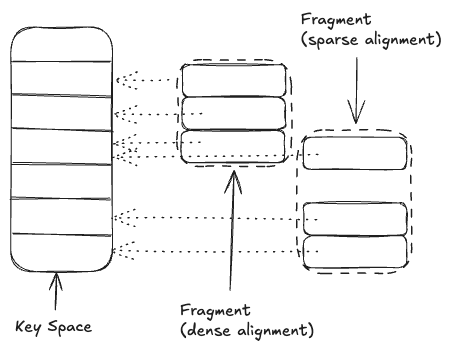
Column groups are stored as partitions, called fragments, which are sorted by key and aligned to exactly one key space.
Fragments have an upper bound on the number of bytes they can store. The partitioning key is used to split data.
Alignment of the fragment to the key space, called key mask, can be dense or sparse [1], and is used to join the column group data with the key space data at read time. From here on, we will refer to fragment with dense alignment as dense fragment. (sparse alignment is not yet implemented)
Each write to a column group creates new fragments and a manifest — a listing of metadata for each new fragment. Metadata includes a file handle, the fragment’s alignment to the key space, and additional fields such as column names and statistics used for pruning during read time.
Column group configuration, such as the latest schema and whether the schema is mutable, is stored in column group metadata. To support column rename and deletion, fragment columns are replaced with column IDs and metadata stores the mapping.
Additionally, metadata holds a listing of all active fragments, called a snapshot.
Metadata must be atomically updated, but to support atomic updates across many column groups, we need a table-wide write-ahead log.
Write-Ahead Log
The write-ahead log (WAL) is a table-wide log of atomic write operations. It contains a sequence of operations detailing the addition/removal of key spaces and fragments, as well as any configuration changes to the column groups.
Similar to the column group snapshot, a listing of all active key spaces, called the key space snapshot, is stored in the WAL.
Periodically, the WAL is flushed. Key space addition/removal operations are flushed into the key space snapshot, and column group fragments and configuration are flushed into column group metadata.
Compaction
Key space compaction is an LSM tree compaction. L0 runs are all potentially overlapping; all other levels have non-overlapping sorted runs. (there are only two levels currently)
L1 initially starts with a key range of b'' to b'0xff', so compaction selects all L0 runs and merges them together.
While writing, if the number of keys grows too large, a new key boundary is introduced and the sorted run is split
in two. Subsequent compactions respect the new set of key ranges and include any existing L1 data alongside overlapping
L0 data.
When a key space is compacted, a displacement map is produced. The displacement map describes how to map a fragment aligned to an origin key space to one or more fragments aligned to a destination key space. (not yet implemented)
L1 ranges determine the key boundaries that form the basis for column group compaction.
The goal of minor compaction is to reduce outer joins, but it does not rewrite fragments’ data to achieve that. It uses displacement maps to re-align fragments to new, higher-level key spaces, purely as a metadata operation. Minor compaction might produce sparse or fragments that reuse a file handle but mask the file rows, called masked fragments. (minor compaction is not yet implemented)
The goal of major compaction is to maintain reasonably large and not too sparse fragments (in the context of alignment), and it will rewrite fragments to achieve that. It is similar to an LSM tree compaction, in that sorted runs are merged, split, and moved across levels, except it uses the key space LSM tree structure to do so. This ensures that fragments are optimal both in the context of a single column group and the entire table.
[1] A fragment is densely aligned to a key space if and only if there are no key gaps in the fragment. For example, consider a key space with the keys 1, 3, 4, 5, 10 and two fragments: fragment one has data for keys 1, 3, 4, 5 and fragment two has data for keys 3, 5. Fragment one is densely aligned to the key space because, within the key range of its rows, every key has a row. Fragment two is sparsely aligned because within the key range of its rows one key lacks a corresponding row, key 4.